Apache Spark Job with Maven
14 May 2016Today, I’m going to show you how to write a sample word count application using Apache Spark. For dependency resolution and building tasks, I’m using Apache Maven. However, you can use the SBT (Simple Build Tool). Most of the Java Developers are familiar with Maven. Hence I decided to show an example using Maven.
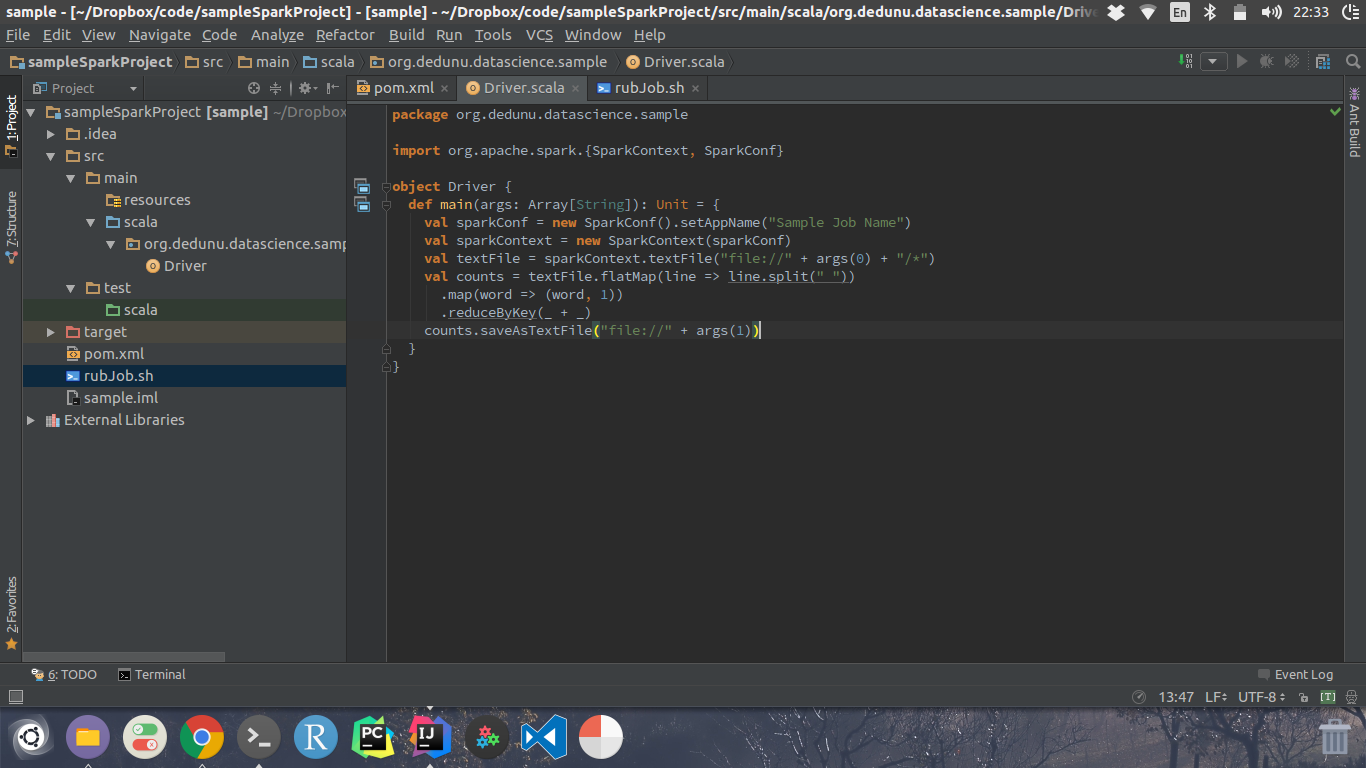
This application is pretty much similar to the WordCount Example of the Hadoop. This job exactly does the same thing. Content of the Drive.scala is given below.
package org.dedunu.datascience.sample
import org.apache.spark.{SparkContext, SparkConf}
object Driver {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("Sample Job Name")
val sparkContext = new SparkContext(sparkConf)
val textFile = sparkContext.textFile("file://" + args(0) + "/*")
val counts = textFile.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.saveAsTextFile("file://" + args(1))
}
}
This job basically reads all the files in the input folder. Then tokenize every word from space (“ ”). Then count each and every word individually. Moreover, you can see that the application is reading arguments from the args variable. The first argument will be the input folder. The second argument will be used to dump the output.
Maven projects need a pom.xml. Content of the pom.xml is given below.
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.dedunu.datascience</groupId>
<artifactId>sample</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<spark.version>1.6.1</spark.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<finalName>sample-Spark-Job</finalName>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<archive>
<manifest>
<mainClass>org.dedunu.datascience.sample.Driver</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id> <!-- this is used for inheritance merges -->
<phase>package</phase> <!-- bind to the packaging phase -->
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<executions>
<execution>
<id>compile</id>
<goals>
<goal>compile</goal>
</goals>
<phase>compile</phase>
</execution>
<execution>
<id>test-compile</id>
<goals>
<goal>testCompile</goal>
</goals>
<phase>test-compile</phase>
</execution>
<execution>
<phase>process-resources</phase>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
Run below command to build the Maven project:
$ mvn clean package
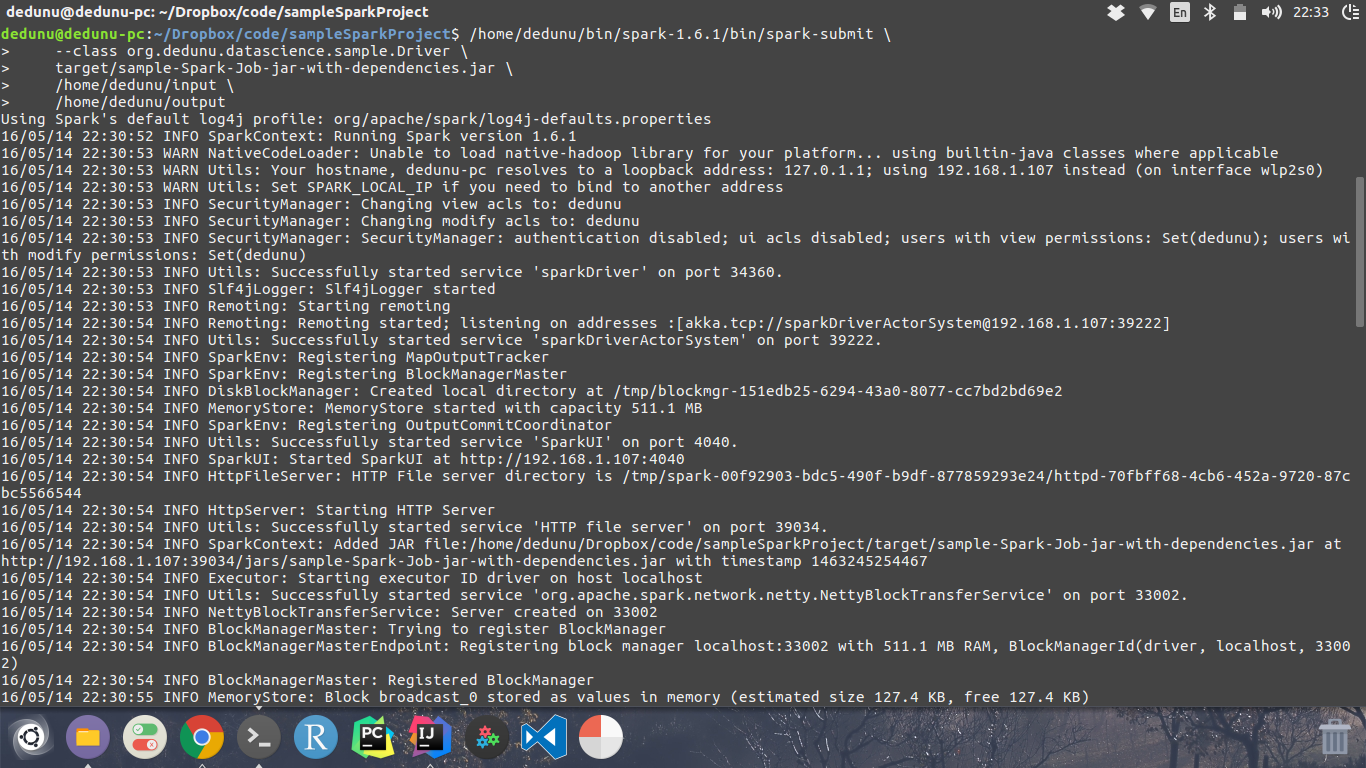
Maven will download all the dependencies and all the other stuff on behalf of you. Then what you need to do is run this job. To run the job, please run below command on your terminal window.
$ /home/dedunu/bin/spark-1.6.1/bin/spark-submit \
--class org.dedunu.datascience.sample.Driver \
target/sample-Spark-Job-jar-with-dependencies.jar \
/home/dedunu/input \
/home/dedunu/output
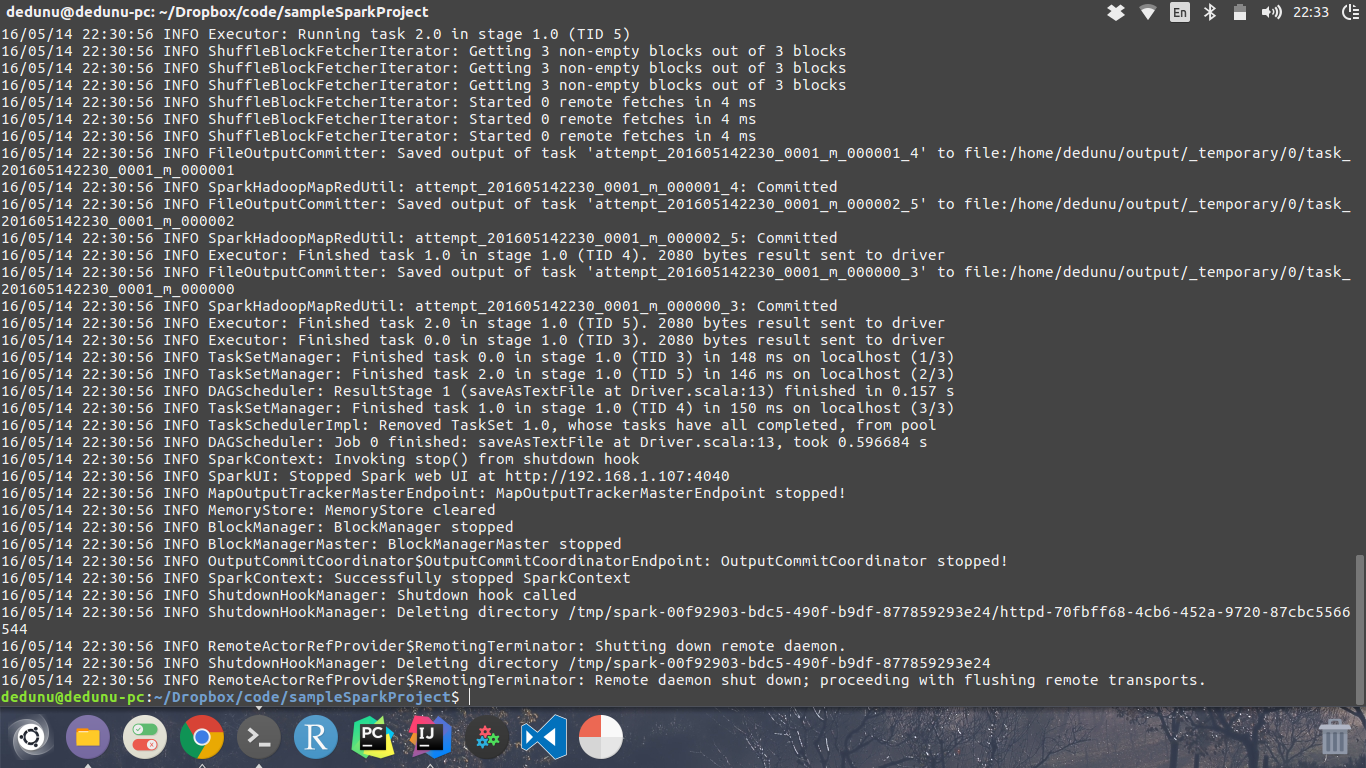
The output of the job will look like below.
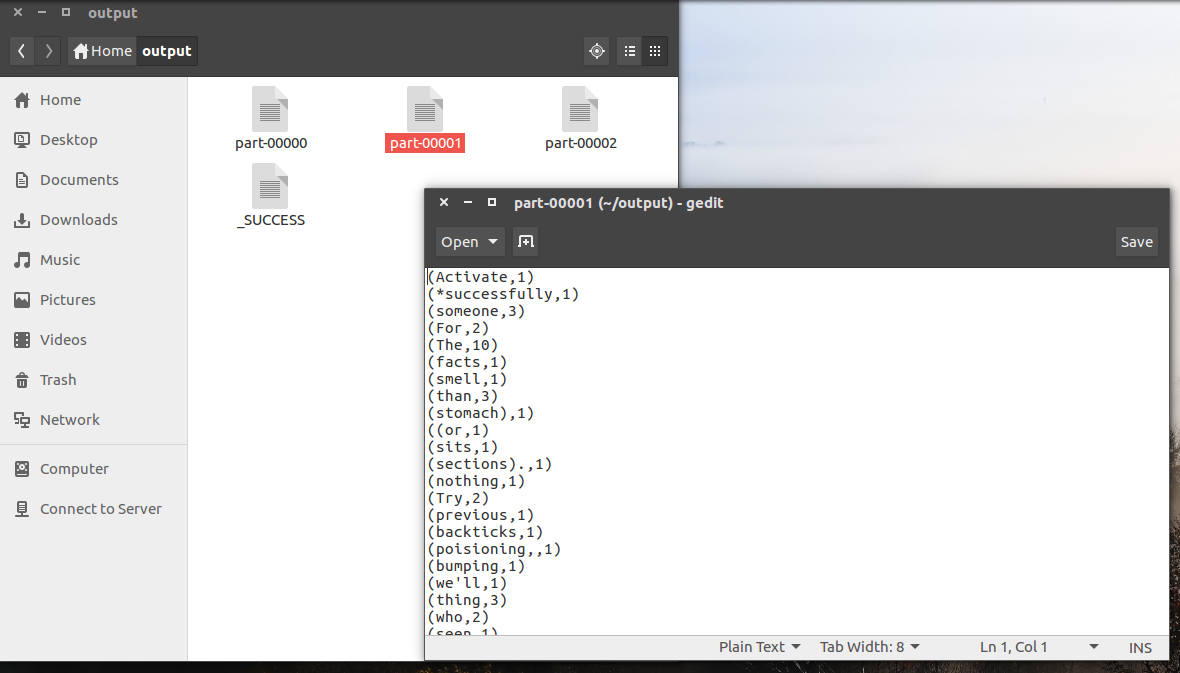
You can find the project on Github - https://github.com/dedunu/spark-example
Enjoy Spark!
Gists
- https://gist.github.com/dedunumax/749a390d97fd20bf0991402c0b29d7a2
- https://gist.github.com/dedunumax/bcf6282d76341ea7b4ae1dd644b46245
Tags
- spark
- maven